The differences between variables stored on the stack versus variables stored on the heap when using the .NET Framework are, on the surface, small. However, if you understand what is happening behind the scenes, they are actually two different worlds.
It is required that you understand a couple of things about variables before understanding where they are stored at. First, there are two main types of variables in the .NET Framework: Value Types and Reference Types. Pointers also exist which is a third type but we are focusing on the 99% here which means value types and reference types.
Value Types
Value Type types inherit from System.ValueType and they are different because they hold the data for the type in their own memory allocation. All the types below are value types:
- bool
- byte
- char
- date
- decimal
- double
- enum
- float
- int
- long
- sbyte
- short
- struct
- uint
- ulong
- ushort
You will notice that all numeric types are value types and most of the items in that list have numeric values like enum and date. There are a couple of oddities in that list, however. Like struct. Even if a struct contains variables that are not value types, the struct is a value type. So, where does a value type live? The stack or the heap? Typically, the stack. You can declare a value type on the heap but that is another discussion for later. Value Type = stack.
Reference Types
Reference types inherit from System.Object and do not contain their own values but a pointer to the value. The list below contains a list of reference types:
- array
- class
- delegate
- interface
- object
- string
The list of reference types is much shorter but most of the .NET Framework is made up of reference types. There is also an oddity in this list: array. Even an array of value types, such as integers, is a reference type. Where do reference type types live? On the heap. Always.
Code Displaying the Differences
Consider the following code that demonstrates the differences between the stack and the heap.
int number1 = 5;
int number2 = 12;
Console.WriteLine($"The value of number1: {number1}");
Console.WriteLine($"The value of number2: {number2}");
//Output
//The value of number1: 5
//The value of number2: 12
Console.ReadKey();
number2 = number1;
Console.WriteLine($"The value of number1: {number1}");
Console.WriteLine($"The value of number2: {number2}");
//Output
//The value of number1: 5
//The value of number2: 5
Console.ReadKey();
number1 = 15;
Console.WriteLine($"The value of number1: {number1}");
Console.WriteLine($"The value of number2: {number2}");
//Output
//The value of number1: 15
//The value of number2: 5
Console.ReadKey();
So, why does this happen? After setting number2 = number1, we changed the value of number1 but number2 didn’t get updated. Why? Well, if you remember from above, value types contain their own data within their own allocated memory so by setting number2 = number1, we gave number2 the same value but they were not the same memory allocation so updating one doesn’t update the other.
Now, lets look at reference types.
Customer customer1 = new Customer
{
Name = "Test Customer 1"
};
Customer customer2 = new Customer
{
Name = "Test Customer 2"
};
Console.WriteLine($"Customer 1 Name: {customer1.Name }");
Console.WriteLine($"Customer 2 Name: {customer2.Name }");
//Output
//Customer 1 Name: Test Customer 1
//Customer 2 Name: Test Customer 2
Console.ReadKey();
customer2 = customer1;
Console.WriteLine($"Customer 1 Name: {customer1.Name }");
Console.WriteLine($"Customer 2 Name: {customer2.Name }");
//Output
//Customer 1 Name: Test Customer 1
//Customer 2 Name: Test Customer 1
Console.ReadKey();
customer1.Name = "Customer 3";
Console.WriteLine($"Customer 1 Name: {customer1.Name }");
Console.WriteLine($"Customer 2 Name: {customer2.Name }");
//Output
//Customer 1 Name: Customer 3
//Customer 2 Name: Customer 3
Console.ReadKey();
customer2.Name = "Customer 4";
Console.WriteLine($"Customer 1 Name: {customer1.Name }");
Console.WriteLine($"Customer 2 Name: {customer2.Name }");
Output:
//Customer 1 Name: Customer 4
//Customer 2 Name: Customer 4
Console.ReadKey();
So, what is going on here? Notice that after setting customer2 = customer1 that updating the name for either customer1 or customer2 updates the other. This is because customer1 and customer2 are reference types. After setting customer2 = customer1, they are pointed to the same memory allocation on the heap so updating either one of them updates the memory that each of them have a pointer to which causes the value of both to change.


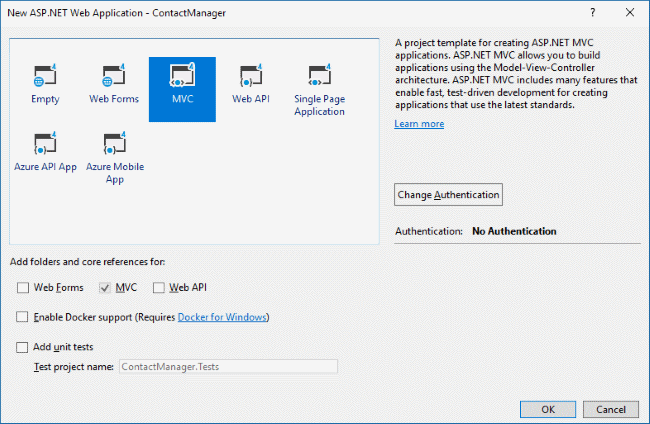
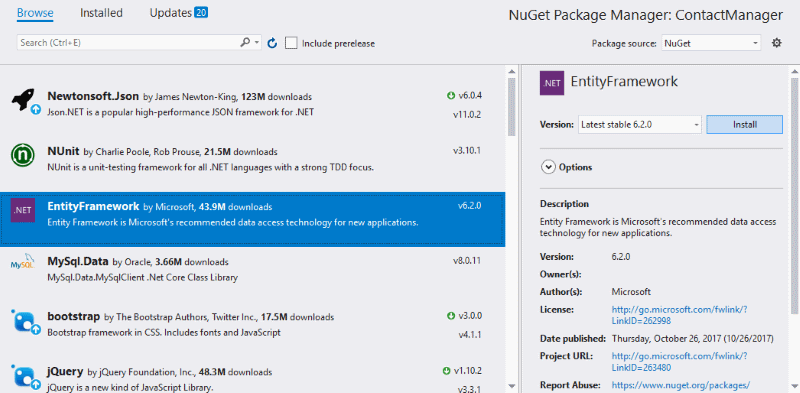
 Let’s get started by using NuGet to add a reference to the Microsoft.AspNet.SignalR library. This will install several different packages to your project including three other Microsoft.AspNet.SignalR libraries and there are a few dependencies on OWIN.
Let’s get started by using NuGet to add a reference to the Microsoft.AspNet.SignalR library. This will install several different packages to your project including three other Microsoft.AspNet.SignalR libraries and there are a few dependencies on OWIN.